快速开始
本页是一份从控制台到 API 调用、第三方工具接入、日志排查和生产上线的完整接入流程。第一次接入建议按顺序完成;已有经验的开发者可以直接跳到「开发者接入」。
接入路径
- 登录 Xima AI 控制台。
- 查看账号余额、可用模型和模型价格。
- 创建 API Key,并按用途设置额度、权限或有效期。
- 用 cURL 完成一次最小请求。
- 在日志页面确认请求、模型、tokens 和费用。
- 再接入 SDK、第三方客户端、代码编辑器或工作流平台。
接入前准备
你需要准备三项信息:
| 信息 | 示例 | 获取方式 |
|---|---|---|
| Base URL | https://console.xima.ai/v1 | 控制台连接信息或本文示例 |
| API Key | sk-xxxxxxxx | 控制台「令牌」或「API Key」页面创建 |
| Model | azure/gpt-5.4-mini | 从控制台「模型与定价」页面复制 |
请求头固定格式:
Authorization: Bearer sk-替换为你的APIKey
Content-Type: application/jsonWARNING
模型 ID 请从控制台复制,不要手写。版本号、大小写、日期后缀和分隔符都必须完全一致。
控制台快速开始
1. 登录控制台
打开 Xima AI 控制台 并完成登录。
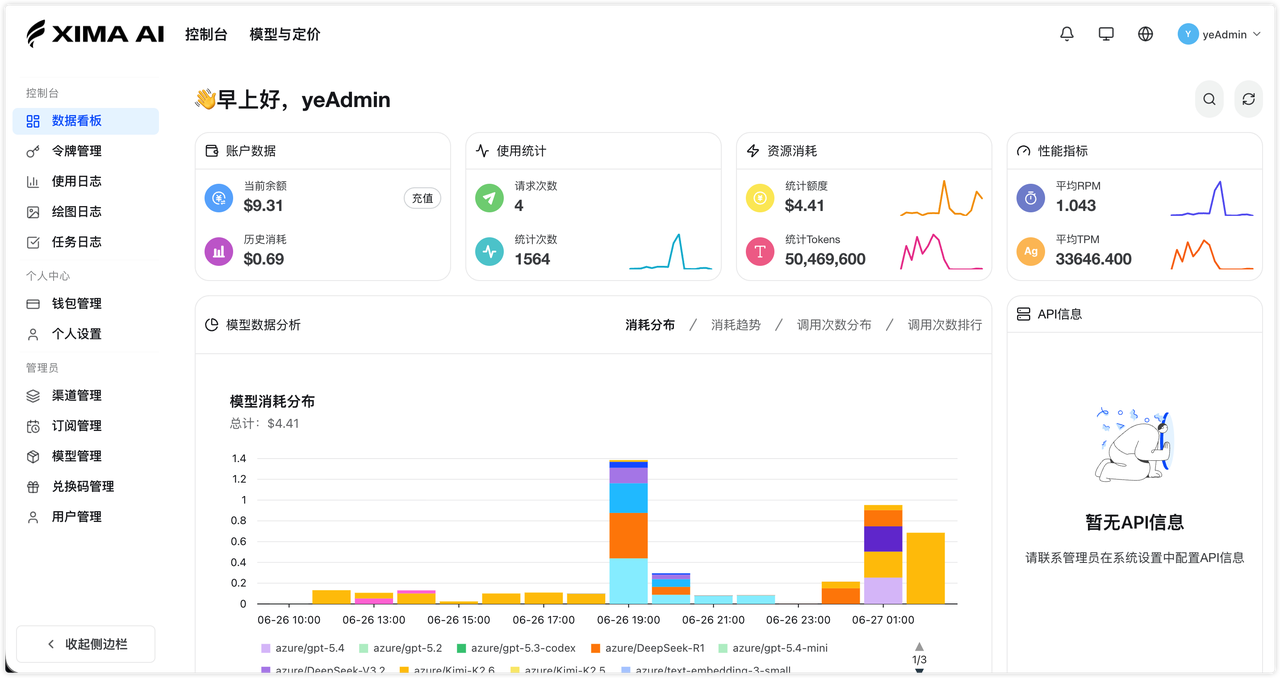
首次登录后建议确认:
- 账户余额或额度是否正常。
- 当前账号可用哪些模型。
- 是否可以创建并复制
sk-...格式的 API Key。 - 是否可以在「日志」页面看到一次测试调用记录。
2. 查看模型和价格
进入控制台的「模型与定价」页面,重点查看:
- 模型名称:接入时填写到请求体的
model字段,必须复制完整模型名。 - 模型能力:聊天、视觉、向量、图片生成、视频生成等能力可能对应不同接口。
- 计费项:输入、输出、缓存读取、缓存创建、图片输入、音频输入或按秒计费。
- 可用状态:如果账号暂时不可用该模型,请更换可用模型或联系支持。
公开文档中的价格统一维护在 模型与价格。快速开始不再重复价格表,避免多个页面价格不同步。
模型名常见注意事项:
- 不要把连字符
-手写成点号.。 - 不要漏掉日期、版本号或后缀。
- 不要把客户端里的展示名当作真实模型名。
- 如果客户端没有自动拉取模型,请从控制台复制后手动添加。
3. 创建 API Key
进入控制台的「令牌」或「API Key」管理页面,点击创建或添加令牌。
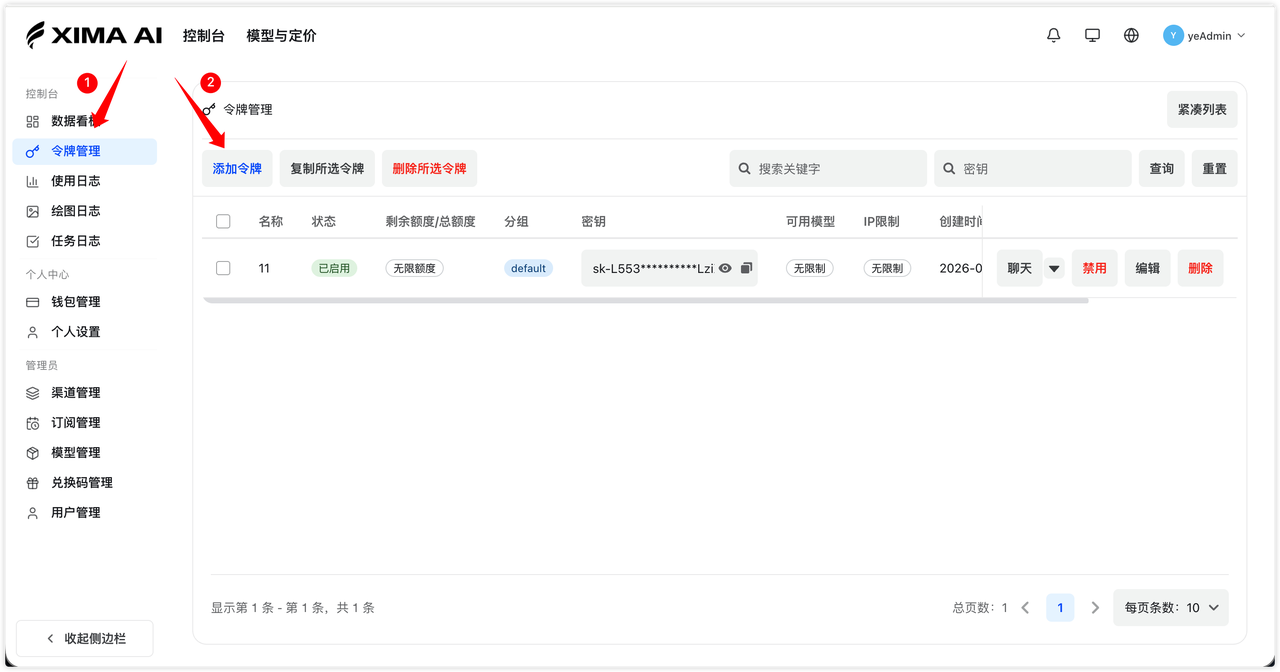
建议按用途命名,例如:
personal-testcursor-devnextchat-mobilelobe-chatcherry-studiodify-workflowprod-server
创建时建议检查以下配置:
| 配置项 | 建议 |
|---|---|
| 名称 | 按用途命名,方便日志排查 |
| 额度 | 测试、演示、第三方工具建议设置固定额度上限 |
| 有效期 | 临时测试 Key 设置较短有效期 |
| 模型限制 | 只开放当前场景需要的模型 |
| IP 白名单 | 生产服务端固定出口 IP 时可以启用 |
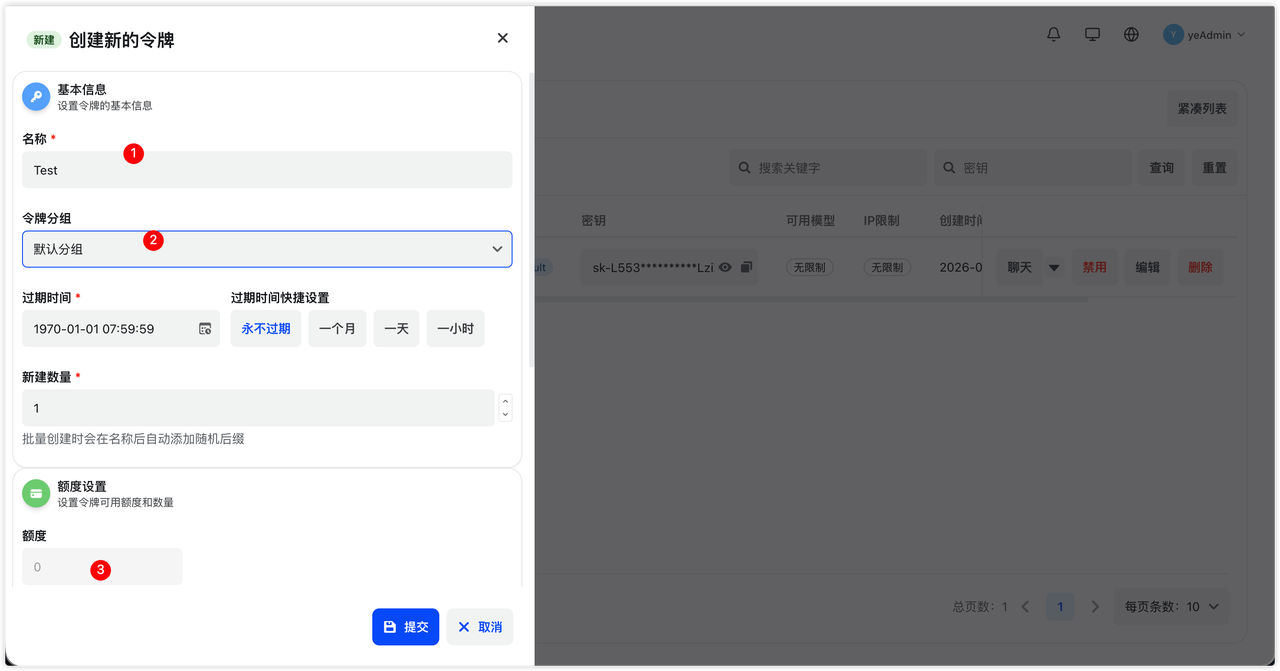
创建后请立即复制并保存完整 Key。Key 等同于调用权限,不要放进前端代码、移动端包体、公开仓库、截图或公开日志。
如果怀疑 Key 泄露,立即禁用或删除旧 Key,再重新创建。
4. 查看额度和余额
进入控制台的「数据看板」或「钱包管理」页面,确认:
- 主账户余额是否充足。
- 当前 API Key 是否设置了额度上限。
- 当前 API Key 是否还有剩余额度。
- 高价模型、长上下文、多轮对话和高并发任务是否会导致额度快速消耗。
如果充值或兑换后未到账,保留订单号、兑换码和截图后联系 Xima AI 支持。
5. 用日志确认调用是否成功
进入控制台的「使用日志」或「日志」页面。日志页面用于确认:
- 请求是否真正到达 Xima AI。
- 使用的是哪个 API Key。
- 调用的是哪个模型。
- 输入 tokens、输出 tokens、缓存 tokens 和费用是否正常。
- 失败请求的状态码、错误信息和 Raw Error。
如果客户端提示「连接失败」,第一步先看日志是否有请求记录:
| 日志情况 | 判断 |
|---|---|
| 日志没有记录 | 请求没有到达 Xima AI,优先检查 Base URL、网络、代理、客户端 Provider 和 Authorization |
| 日志有失败记录 | 查看状态码、模型名、tokens 和错误详情 |
| 日志有 Raw Error | 截图或复制 Raw Error 后再联系支持 |
开发者接入
接口路径
Xima AI 通常兼容 OpenAI 风格接口,常见路径如下:
| 能力 | 路径 | 完整示例 |
|---|---|---|
| 聊天补全 | /chat/completions | https://console.xima.ai/v1/chat/completions |
| 模型列表 | /models | https://console.xima.ai/v1/models |
| 向量嵌入 | /embeddings | https://console.xima.ai/v1/embeddings |
| 图片生成 | /images/generations | https://console.xima.ai/v1/images/generations |
如果某个路径返回 404、模型不存在或能力不支持,请以控制台文档和模型说明为准。
配置环境变量
建议把 Base URL、API Key 和默认模型放到环境变量中:
export XIMA_BASE_URL="https://console.xima.ai/v1"
export XIMA_API_KEY="sk-替换为你的APIKey"
export XIMA_MODEL="azure/gpt-5.4-mini"如果你从控制台复制到的 Base URL 已经包含 /v1,请求路径只需要继续拼接 /chat/completions,不要写成 /v1/v1/chat/completions。
cURL 最小测试
先用非流式请求测试连通性:
curl "$XIMA_BASE_URL/chat/completions" \
-H "Authorization: Bearer $XIMA_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "'"$XIMA_MODEL"'",
"messages": [
{
"role": "user",
"content": "你好,请用一句话介绍 Xima AI。"
}
],
"temperature": 0.7
}'如果 cURL 成功,说明 Base URL、API Key、模型名和网络基本可用;如果第三方客户端仍失败,优先排查客户端配置。
查询模型列表:
curl "$XIMA_BASE_URL/models" \
-H "Authorization: Bearer $XIMA_API_KEY"Python 接入
安装依赖:
pip install openai示例代码:
import os
from openai import OpenAI
client = OpenAI(
api_key=os.environ["XIMA_API_KEY"],
base_url=os.environ.get("XIMA_BASE_URL", "https://console.xima.ai/v1"),
)
response = client.chat.completions.create(
model=os.environ.get("XIMA_MODEL", "azure/gpt-5.4-mini"),
messages=[
{"role": "user", "content": "测试一下连接是否正常。"}
],
)
print(response.choices[0].message.content)Python 流式输出
import os
from openai import OpenAI
client = OpenAI(
api_key=os.environ["XIMA_API_KEY"],
base_url=os.environ.get("XIMA_BASE_URL", "https://console.xima.ai/v1"),
)
stream = client.chat.completions.create(
model=os.environ.get("XIMA_MODEL", "azure/gpt-5.4-mini"),
messages=[
{"role": "user", "content": "请分三点说明流式输出的好处。"}
],
stream=True,
)
for chunk in stream:
delta = chunk.choices[0].delta.content
if delta:
print(delta, end="", flush=True)Node.js 接入
安装依赖:
npm install openai示例代码:
import OpenAI from "openai";
const client = new OpenAI({
apiKey: process.env.XIMA_API_KEY,
baseURL: process.env.XIMA_BASE_URL || "https://console.xima.ai/v1"
});
const response = await client.chat.completions.create({
model: process.env.XIMA_MODEL || "azure/gpt-5.4-mini",
messages: [
{ role: "user", content: "测试一下连接是否正常。" }
]
});
console.log(response.choices[0].message.content);cURL 流式输出
聊天产品、长文本生成和 Agent 场景通常建议开启流式输出:
curl -N "$XIMA_BASE_URL/chat/completions" \
-H "Authorization: Bearer $XIMA_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "'"$XIMA_MODEL"'",
"messages": [
{
"role": "user",
"content": "请分三点说明流式输出的好处。"
}
],
"stream": true
}'客户端需要按 Server-Sent Events 逐段读取返回内容。生产环境建议先用非流式请求打通,再开启 stream: true。
Embedding 示例
向量模型使用 /embeddings 路径:
curl "$XIMA_BASE_URL/embeddings" \
-H "Authorization: Bearer $XIMA_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "azure/text-embedding-3-small",
"input": "Xima AI 统一模型网关"
}'Embedding 只按输入 tokens 计费,具体价格以 模型与价格 和控制台用量明细为准。
第三方工具接入
独立 AI 客户端
适用于 NextChat、LobeChat、Chatbox、Cherry Studio、OpenWebUI 等支持 OpenAI 兼容接口的客户端。
通用填写方式:
| 配置项 | 填写内容 |
|---|---|
| Provider / 供应商 | OpenAI Compatible、自定义 OpenAI、自定义 API 等 |
| API Base / Base URL | https://console.xima.ai/v1 |
| API Key | 控制台创建的 sk-... |
| Model | 从 Xima AI 控制台复制模型名称 |
注意事项:
- Base URL 末尾通常需要带
/v1。 - 如果客户端没有自动拉取模型列表,请在「自定义模型」中手动输入控制台模型名。
- 如果同一个客户端里有多个 Provider,确认当前对话选中的是 Xima AI 对应配置。
- 接入后先发一句短消息测试,再到 Xima AI 日志页确认请求记录。
AI 代码编辑器
适用于 Cursor 一类代码编辑器:
- 打开设置中的模型或 API 配置页。
- 选择 OpenAI Compatible、OpenAI Override 或自定义 OpenAI 方式。
- Base URL 填写
https://console.xima.ai/v1。 - API Key 填写
sk-...。 - 在模型列表中开启或手动添加你要使用的模型。
- 保存后发起一次短测试。
- 回到 Xima AI 日志页确认请求是否到达。
常见问题:
- 只填了 API Key,忘记打开模型开关。
- 模型名称和控制台展示不一致。
- Base URL 漏写
/v1或重复写了/v1/v1。 - 编辑器里有多个 Provider,当前会话没有选中 Xima AI 对应配置。
Dify / 工作流平台
适用于 Dify、n8n、Coze 等可配置 OpenAI 兼容接口的平台。
通用步骤:
- 新增模型供应商,选择 OpenAI Compatible 或自定义 OpenAI。
- API Base 填写
https://console.xima.ai/v1。 - API Key 填写控制台创建的
sk-...。 - 手动添加模型名称,或通过模型列表接口拉取。
- 先创建一个最小测试节点,只发送一句短文本。
- 测试成功后再接入长工作流、文件解析、多轮对话或批量任务。
建议:
- 给工作流平台单独创建一个 API Key。
- 给该 Key 设置额度上限。
- 避免工作流失败后无限重试。
- 失败时先到 Xima AI 日志页查看是否有请求记录。
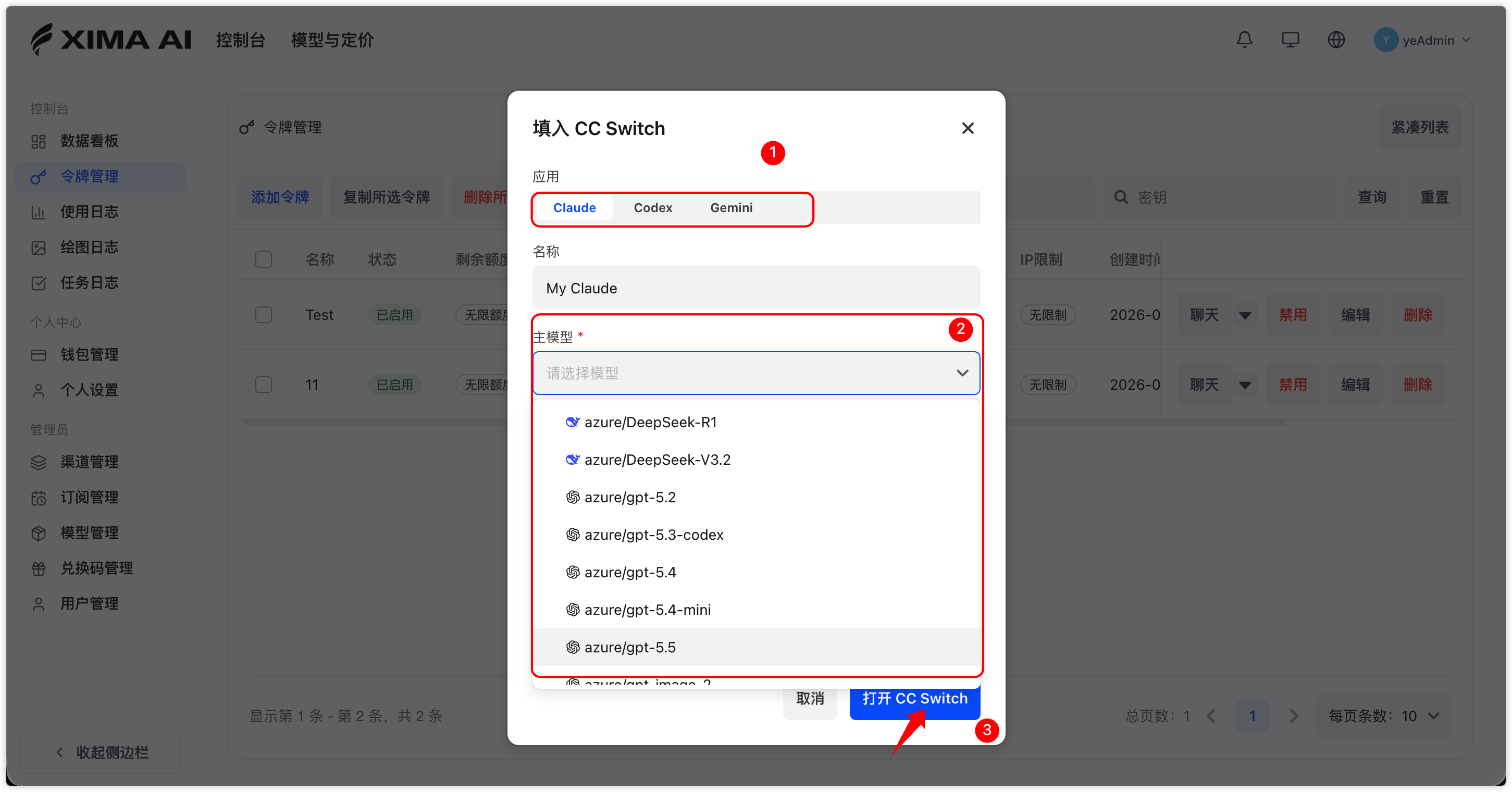
CC Switch
如果控制台令牌页提供 CC Switch 导入入口,可按以下方式操作:
- 在「令牌管理」页面,选择需要操作的令牌。
- 选择 CC Switch。
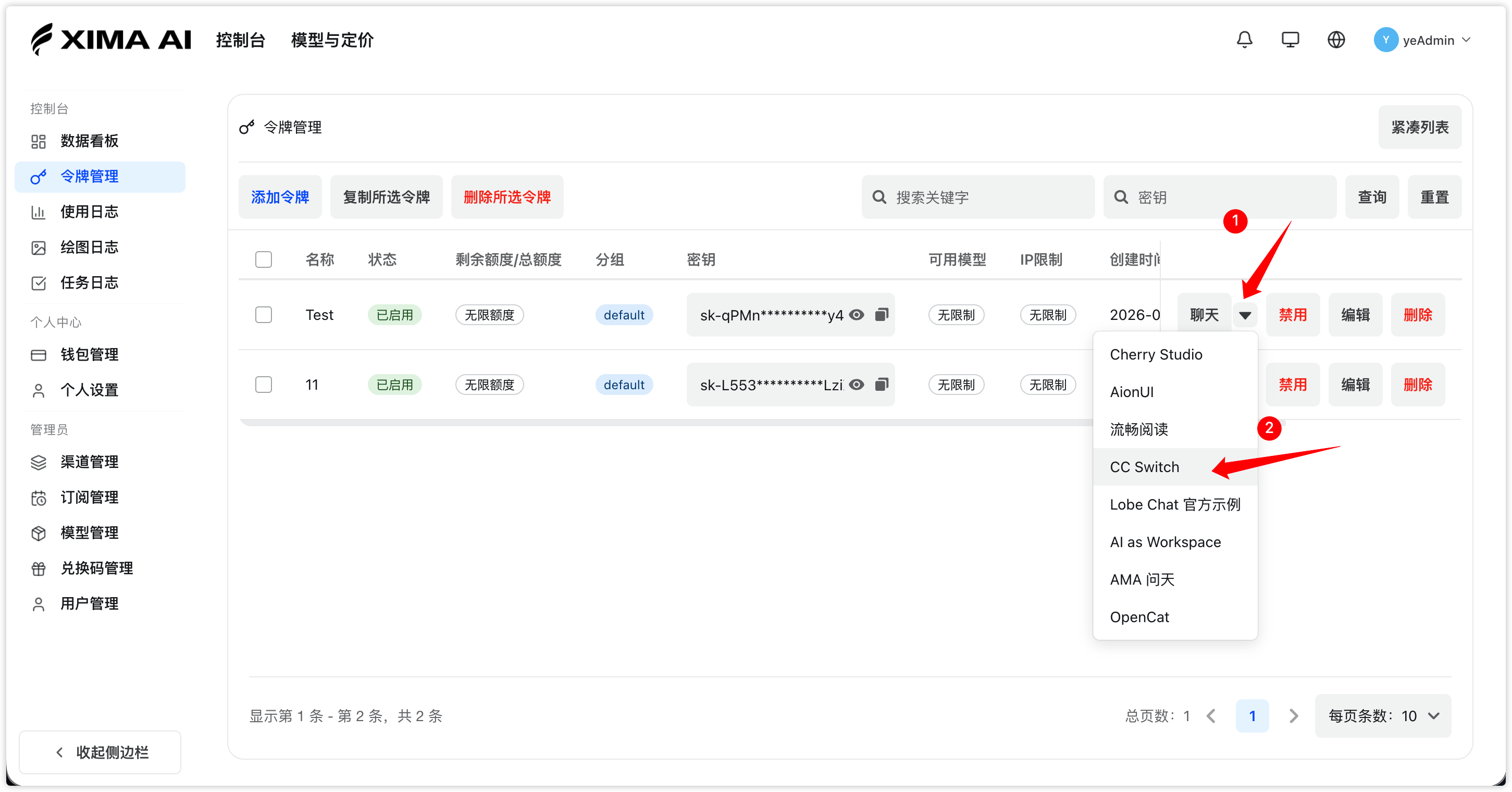
- 选择需要导入的 CLI,例如 Claude CLI、Codex 或 Gemini。
- 选择导入的模型。
- 点击打开 CC Switch,通过唤起应用自动导入。

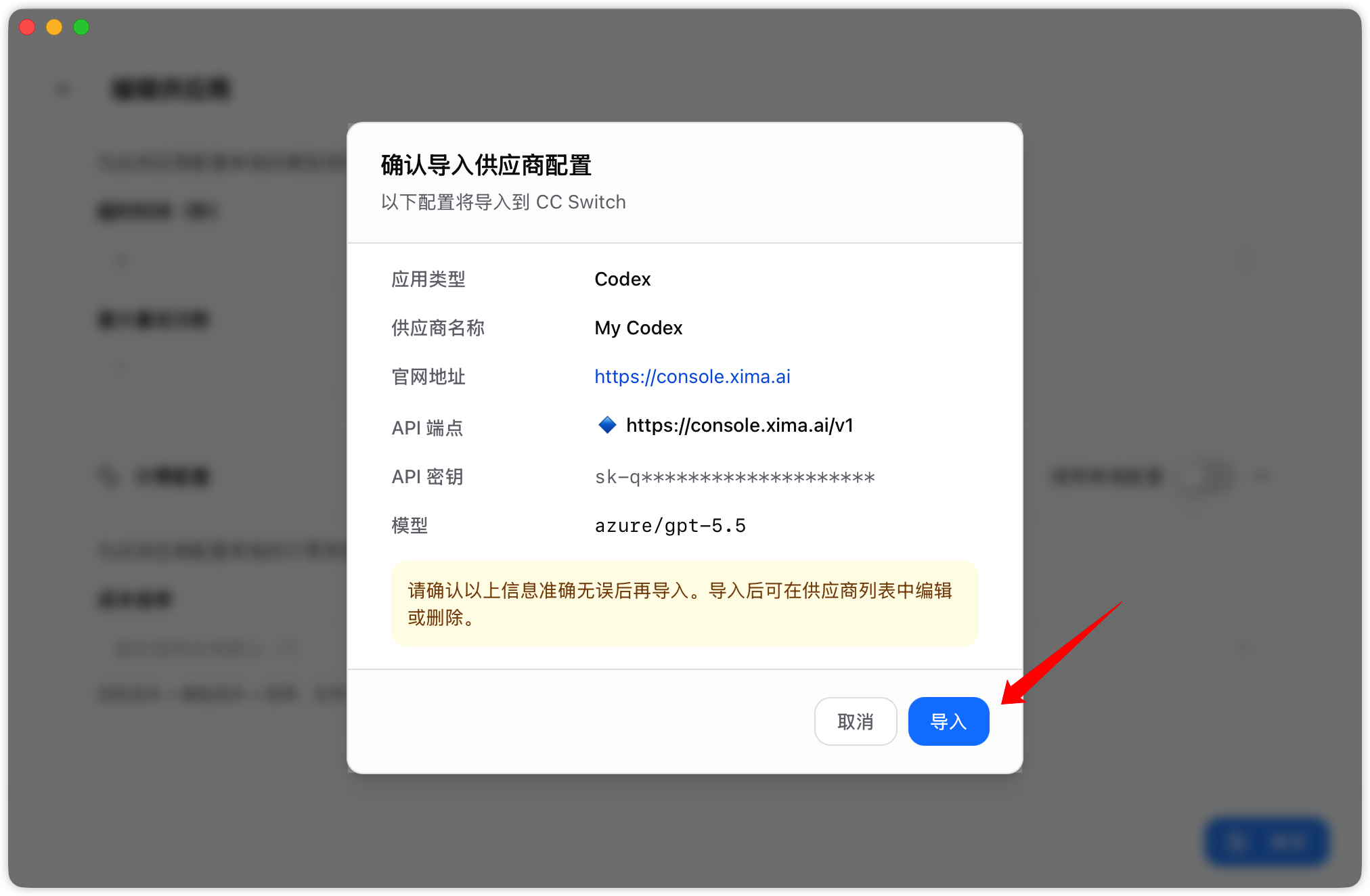
如果唤起失败,优先检查本地是否已安装 CC Switch,以及浏览器是否允许打开外部应用。
常见报错速查
| 状态码 / 报错 | 常见表现 | 优先检查 |
|---|---|---|
400 Bad Request | invalid_request_error、model_not_found、参数错误 | 模型名、JSON 格式、messages、上下文长度、模型能力 |
401 Unauthorized | Invalid API Key、身份验证失败 | API Key 是否完整、是否有空格、请求头格式、Key 是否被禁用 |
403 Forbidden | Total quota is not enough、Token quota is not enough、insufficient_quota | 主账户余额、Key 额度、模型权限、IP 白名单 |
404 Not Found | 接口不存在、模型不存在 | Base URL、接口路径、模型名、是否重复 /v1 |
408 Timeout / timeout | 请求超时、连接失败 | 网络、代理、DNS、输入长度、客户端 timeout |
429 Too Many Requests | Rate limit reached、Requests too frequent | 请求频率、并发、RPM、TPM、重试策略 |
500 Internal Server Error | Internal Server Error、Bad Gateway | 平台或上游渠道异常,查看 Raw Error |
503 Service Unavailable | No available channels、服务不可用 | 当前模型无健康渠道,换模型并联系支持 |
| 上下文过长 | context_length_exceeded | 输入内容、历史对话、文档长度、max_tokens |
| 返回为空或截断 | 输出为空、内容突然停止 | max_tokens、stop、流式读取逻辑 |
| CORS / 浏览器跨域 | 浏览器前端直接请求失败 | 不要在浏览器暴露 API Key,改用后端转发 |
| 日志无记录 | 客户端报错但控制台无日志 | 请求没有到 Xima AI,查 Base URL、网络、客户端 Provider |
常见报错处理
400 Bad Request / 请求错误
常见原因:
- 模型名称写错或不完整。
messages格式不正确。- JSON 格式错误。
- 参数类型错误,例如把数字写成字符串。
- 当前模型不支持图片、工具调用、JSON 模式或其他特殊参数。
- 历史对话太长,或
max_tokens设置过高。
处理方式:
- 用本文 cURL 示例做最小请求测试。
- 从控制台复制模型名,不要手写。
- 确认
messages是数组,且每条消息包含role和content。 - 删除不确定的高级参数,只保留
model、messages、temperature。 - 如果是上下文超限,缩短输入、裁剪历史或降低
max_tokens。 - 如果是多模态请求,确认模型确实支持图片、音频或文件输入。
401 Unauthorized / 凭证无效
常见原因:
- API Key 填错、少复制字符或包含多余空格。
- 请求头不是
Authorization: Bearer sk-...。 - Key 已被禁用、删除或过期。
- Base URL 写错,请求发到了其他服务。
- 当前账号状态受限。
处理方式:
- 重新复制控制台中的
sk-...。 - 确认请求头格式为
Authorization: Bearer sk-你的APIKey。 - 确认 Base URL 为
https://console.xima.ai/v1。 - 新建一个测试 Key 重新验证。
- 若仍失败,查看日志或联系 Xima AI 支持确认账号状态。
403 Forbidden / 无权限或额度不足
常见原因:
- 主账户余额不足。
- 当前 Key 额度耗尽。
- 当前账号没有该模型权限。
- Key 设置了模型限制、分组限制或 IP 白名单。
- 调用来源 IP 不在白名单内。
处理方式:
- 到控制台检查主账户余额。
- 到令牌列表检查该 Key 的额度上限和剩余额度。
- 换一个确定可用的模型测试。
- 检查 Key 是否限制模型或 IP。
- 如需模型权限或更高额度,联系 Xima AI 支持。
404 Not Found / 接口或模型不存在
常见原因:
- Base URL 路径错误,例如漏写
/v1。 - 重复写了
/v1/v1。 - 接口路径拼错,例如
/chat/completion少了s。 - 模型名称不存在。
- 当前模型不支持所调用的接口能力。
处理方式:
- Base URL 使用
https://console.xima.ai/v1。 - 聊天接口完整地址为
https://console.xima.ai/v1/chat/completions。 - 从控制台复制模型名称。
- 检查客户端是否自动拼接了
/v1。 - 到日志页面查看实际错误。
408 Timeout / 连接失败 / 请求超时
常见原因:
- 本地网络不稳定。
- 代理、防火墙或 DNS 异常。
- 输入过长,模型响应慢。
- 客户端 timeout 设置太短。
- 平台或上游模型临时繁忙。
处理方式:
- 用 cURL 最小请求测试网络和 Key。
- 检查代理、防火墙和 DNS。
- 缩短输入内容,降低
max_tokens。 - 在 SDK 或客户端中适当调大 timeout。
- 查看 Xima AI 日志,确认请求是否到达平台。
429 Too Many Requests / 请求过多或限流
常见原因:
- 请求频率过高。
- 并发过高。
- 客户端自动重试导致请求堆积。
- 上游模型有 RPM 或 TPM 限制。
处理方式:
- 降低并发和请求频率。
- 加入指数退避重试,例如 1 秒、2 秒、4 秒递增。
- 避免无限重试。
- 聊天客户端可等待 10-30 秒后重试。
- 生产业务需要更高并发时,联系 Xima AI 支持确认限额。
500 / 503 / 渠道异常
常见原因:
- 当前模型对应的上游渠道临时不可用。
- 上游供应商宕机、限流或返回异常。
- 平台暂时没有健康通道可用。
- 网络链路或网关异常。
处理方式:
- 先重试一次,确认是否为偶发问题。
- 换用另一个可用模型测试。
- 如果同一模型持续失败,到日志页复制错误详情或 Raw Error。
- 联系 Xima AI 支持,并提供请求时间、模型名、Key 名称和日志截图。
上下文过长 / Token 超限
处理方式:
- 缩短输入内容。
- 只保留最近必要的对话历史。
- 长文档先分段摘要,再提交给模型。
- 降低
max_tokens。 - 换用上下文更长的模型。
返回内容为空或被截断
处理方式:
- 增大
max_tokens。 - 检查并移除不必要的
stop参数。 - 非流式调用读取
response.choices[0].message.content。 - 流式调用时确认循环读取全部 chunk。
流式输出异常 / SSE 解析失败
处理方式:
- 先关闭
stream,用非流式请求验证模型可用。 - 确认客户端或网关支持 SSE。
- 正确处理
[DONE]。 - 浏览器前端不要直接暴露 API Key,应通过后端转发。
CORS / 浏览器跨域错误
浏览器前端不要直接调用 Xima AI API,也不要在前端代码中放置 sk-...。推荐架构是:
- 前端调用自己的后端接口。
- 后端从环境变量读取 Xima AI API Key。
- 后端请求 Xima AI,再把安全处理后的结果返回前端。
日志里没有请求记录
常见原因:
- 请求没有发送到 Xima AI。
- Base URL 写错。
- DNS、代理或网络层拦截。
- 客户端配置保存后未生效。
- 当前会话没有选中 Xima AI 的 Provider。
处理方式:
- 确认 Base URL 是
https://console.xima.ai/v1。 - 用 cURL 直接请求测试。
- 检查客户端是否存在多个供应商配置。
- 如果 cURL 有日志而客户端没有日志,优先排查客户端配置。
- 重新保存客户端配置并重启客户端。
日志排查方法
当出现「能打开客户端但无法回复」「前端显示连接失败」「代码没有明显报错」等问题时,按下面顺序排查:
- 打开 Xima AI 控制台。
- 进入「日志」。
- 按时间找到失败请求。
- 检查以下字段。
| 字段 | 重点看什么 |
|---|---|
| 时间 | 是否与你刚刚发起请求的时间一致 |
| 类型 | 是消费、失败请求还是其他记录 |
| 令牌 | 是否使用了正确的 sk-... |
| 模型 | 是否为你想调用的模型,是否拼写完全一致 |
| 状态码 | 400、401、403、404、408、429、500、503 等 |
| 提示 Token | 输入内容是否异常过长 |
| 完成 Token | 输出是否被截断或异常为空 |
| 消耗 | 是否符合预期,是否出现异常高额消耗 |
| 详情 / Raw Error | 上游返回的底层错误,联系支持时最有用 |
判断逻辑:
- 日志没有记录:请求没到 Xima AI,查 Base URL、网络、代理、客户端配置。
- 日志有 401:查 API Key 和 Authorization。
- 日志有 403:查余额、Key 额度、模型权限和 IP 限制。
- 日志有 400:查模型名、参数和上下文长度。
- 日志有 429:降并发、等 10-30 秒、加入重试退避。
- 日志有 500/503:通常是平台或上游通道异常,换模型并联系支持。
联系支持时建议提供:
- 请求时间。
- Key 名称,不要直接发送完整
sk-...。 - 模型名称。
- 状态码和 Raw Error。
- 客户端名称和 Base URL 配置截图。
- 是否能用本文 cURL 最小请求复现。
安全与最佳实践
- API Key 只保存在服务端、环境变量或密钥管理工具中。
- 不要在前端网页、移动端包体、公开仓库或截图中暴露 API Key。
- 生产环境和测试环境使用不同 Key。
- 第三方客户端使用独立 Key,并设置额度上限。
- 不建议给测试 Key 或第三方客户端 Key 开启无限额度。
- 定期查看日志,关注异常高频调用、失败请求和额度消耗。
- 如果项目下线、人员离职或怀疑泄露,及时禁用或删除相关 Key。
- 代码调用应设置 timeout、重试次数和指数退避,避免无限重试。
- 生产业务建议记录请求 ID、模型名、耗时、状态码和错误详情,便于排查。
- 客户端或工作流平台中如果存在自动重试、自动续写、自动 Agent 循环,应额外设置调用上限。
- 用于演示、测试、课程、分享的 Key 建议临时创建,用完删除。